Building a custom news feed
- 16 mins
In this article, I will explain how to create a website that shows you the latest post from your favorite blog, newspaper, or whatever with RSS/Atom feed support.
- I will explain why to do it
- Where you can find it
- The Architecture of the system with some code snippets
- How I deployed the components (without spending money)
- How you can use the project to deploy your news aggregation
- Eventual future developments
Ok, but Why?
Well, I like to write and do some weekend projects but the main reason is that I use Linkedin mainly to read the latest news from tech blogs. The drawback is that I need to constantly see motivational post ![]() , the latest (fake) success story
, the latest (fake) success story ![]() , the nth financial advice I don’t need
, the nth financial advice I don’t need ![]() , the top 10 moves that will make me rich
, the top 10 moves that will make me rich ![]() bla bla bla.
bla bla bla.
I was wondering if there is a way to keep track of the latest news from my favorites tech blogs without being costantly exposed to all that crap and I remembered of RSS and Atom feeds. I downloaded a feed reader extension in my favorite browser and used it for a while, then I thought that instead of having it in my browser, It might be useful to create a website so that whoever has the same need can use it.
It is also an open-source project so you can contribute to it, you can improve it, can propose to support new blogs, or can download it and built your website.
Last but not least the project was really useful to experiment with technologies I was curious to deepen.
Where to find it
The Design
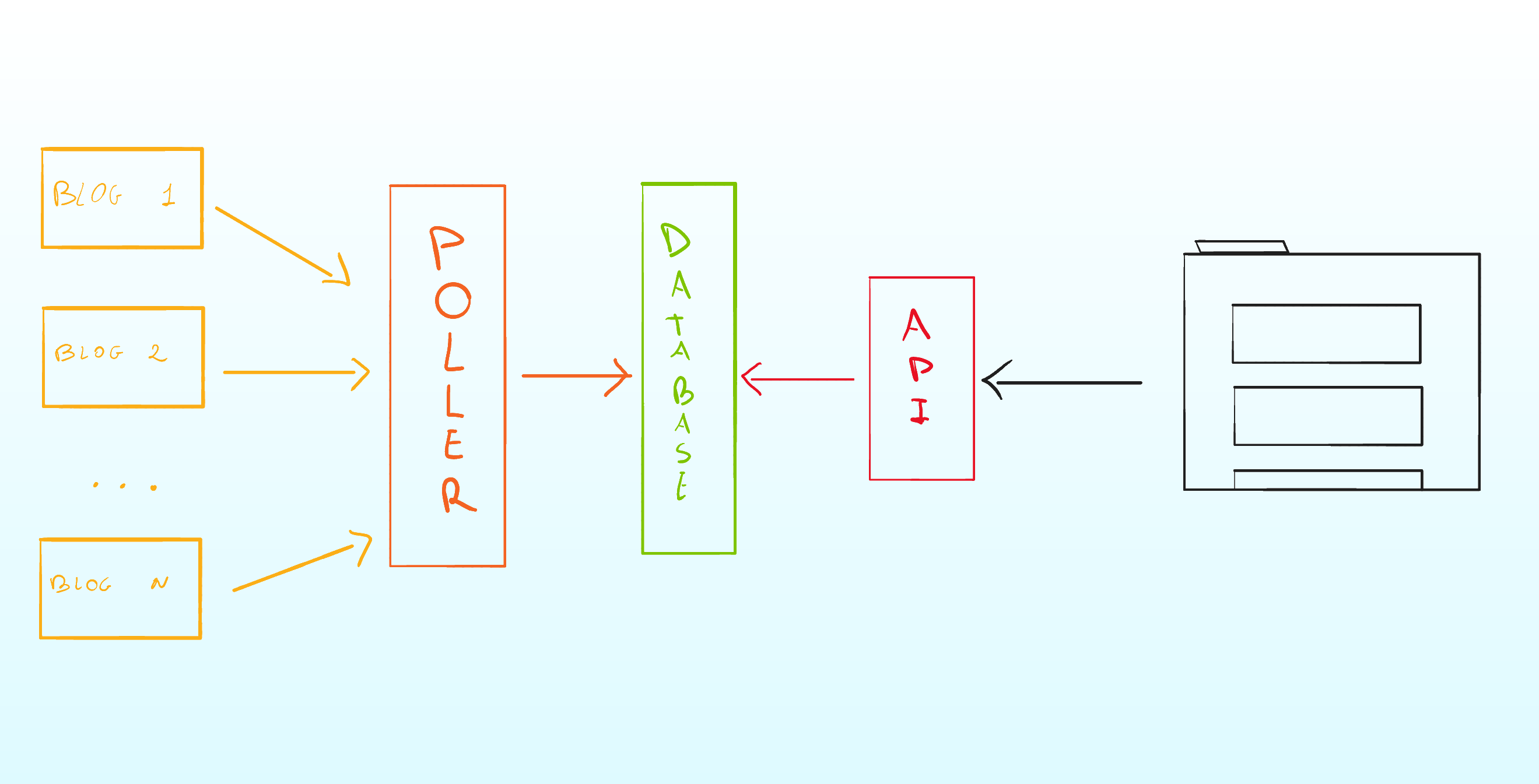
As you can see from the cover image above, the design of the whole system is very simple: we have a poller that listens periodically to the feeds and updates a database, and we have an API that exposes the articles in the database to the web app, and we have a web app that lets you access the latest articles in your web browser.
The website is minimal, it only presents the title of the article, its source, the authors, categories if any, and the publish date. By clicking on the article you will be redirected to the main blog to read it.
 The main involved technologies are:
The main involved technologies are:
- Java + Quarkus for the backend, because I was curious to deepen how it works (expecially for the native executable part)
- Angular for the front end for the same reason.
The database
The database layer is a Database-as-a-Service instance from MongoDB. It is deployed in Google Cloud at eu-west-1 and is a free (shared) tier instance.
The Poller
To listen to the feeds I have googled around for a while and I have found an amazing integration framework: Apache Camel.
Camel integration is based on three simple concepts: routes that make a source and a destination communicate, messages to exchange and processors to eventually elaborate messages in the middle. It has also quarkus components to support native image compilation, Hibernate and JPA, and so on… ![]()
![]() . I fell in love with it immediately. Let’s see the code.
The first class is PollerRoute.java which is the Camel equivalent of the main class:
. I fell in love with it immediately. Let’s see the code.
The first class is PollerRoute.java which is the Camel equivalent of the main class:
import io.quarkus.logging.Log;
import org.apache.camel.builder.RouteBuilder;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.context.ApplicationScoped;
import javax.transaction.Transactional;
import java.util.List;
@ApplicationScoped
public class PollerRoute extends RouteBuilder {
@ConfigProperty(name = "pone.feed")
private List<String> feedList;
@ConfigProperty(name = "pone.refresh")
private Integer refresh;
@ConfigProperty(name = "pone.refresh.limit")
private Integer refreshLimit;
@Transactional
@Override
public void configure() throws Exception {
Log.info(feedList);
feedList.forEach(url ->{
from("rss:" + url + "?alt=rss&splitEntries=false&delay="+refresh+"&repeatCount="+refreshLimit)
.process(new FeedProcessor())
.log("${body}")
.split(body())
.bean(FeedBean.class, "upsert");
});
}
}
The class gets the feed list from the application.properties and for each feed, it gets the entries, parses the entry into a FeedBean object using the FeedProcessor(), and then inserts/updates the entry using a FeedBean method.
The FeedBean class is:
import io.quarkus.mongodb.panache.PanacheMongoEntityBase;
import io.quarkus.mongodb.panache.common.MongoEntity;
import org.bson.codecs.pojo.annotations.BsonId;
import java.util.Date;
@MongoEntity(collection="NewsFeed")
public class FeedBean extends PanacheMongoEntityBase {
@BsonId
public String title;
public String authors;
public String categories;
public String link;
public String src;
public Date date;
public Date updateDate;
public FeedBean(){}
public static void upsert(FeedBean f){
f.persistOrUpdate();
}
}
It extends PanacheMongoEntityBase that is a Quarkus utility to support ORM for MongoDB (more or less).
The FeedProcessor is:
import com.rometools.rome.feed.synd.SyndCategory;
import com.rometools.rome.feed.synd.SyndEntry;
import com.rometools.rome.feed.synd.SyndFeed;
import com.rometools.rome.feed.synd.SyndPerson;
import org.apache.camel.Exchange;
import org.apache.camel.Message;
import org.apache.camel.Processor;
import java.util.List;
public class FeedProcessor implements Processor {
public FeedBean syndEntryToFeedBean(SyndEntry entry, String src){
FeedBean fb = new FeedBean();
String authors = entry.getAuthors()
.stream()
.map(SyndPerson::getName)
.reduce((a1,a2) -> a1.concat(";").concat(a2))
.orElse("");
fb.authors = authors.isEmpty()? entry.getAuthor(): authors;
fb.title = entry.getTitle();
fb.categories = entry.getCategories()
.stream()
.map(SyndCategory::getName)
.reduce((a1,a2) -> a1.concat(";").concat(a2))
.orElse("");;
fb.link = entry.getLink();
fb.date = entry.getPublishedDate();
fb.updateDate = entry.getUpdatedDate();
fb.src = src;
return fb;
}
@Override
public void process(Exchange exchange) throws Exception {
Message m = exchange.getMessage();
SyndFeed f = (SyndFeed) m.getBody();
List<SyndEntry> entryList = f.getEntries();
String src = f.getLink();
List<FeedBean> feedList = entryList.stream().map(entry -> this.syndEntryToFeedBean(entry, src)).toList();
exchange.getMessage().setBody(feedList);
}
}
The method FeedProcessor.syndEntryToFeedBean is a simple converter, it extracts useful info from a SyndEntry object and converts them into a FeedBean instance.
The API
The API is so simple that there is no need to detail. It executes a paginated query using the FeedBean we have seen above and returns the latest articles. It can also return the maximum number of pages so that the UI will know it.
import io.quarkus.logging.Log;
import io.quarkus.panache.common.Page;
import io.quarkus.panache.common.Sort;
import io.quarkus.runtime.StartupEvent;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.event.Observes;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
import java.util.List;
@Path("feeds")
public class FeedResource {
@ConfigProperty(name = "news.aggregator.page.size")
Integer pageSize;
Integer pageSizeDefault = 30;
@ConfigProperty(name = "quarkus.mongodb.connection-string")
String mongoString;
void onStart(@Observes StartupEvent ev) {
Log.info("The mongo string is: " + mongoString);
Log.info("Page size is: " + pageSize);
}
@GET
@Path("/{idx}")
@Produces(MediaType.APPLICATION_JSON)
public List<FeedBean> getPage(Integer idx) {
Integer ps = pageSize == null? pageSizeDefault : pageSize;
return FeedBean.findAll(Sort.by("date", "updateDate").descending()).page(Page.of(idx, ps)).list();
}
@GET
@Path("/pages")
@Produces(MediaType.APPLICATION_JSON)
public double getNumberOfPagse() {
Integer ps = pageSize == null? pageSizeDefault : pageSize;
return Math.floor(FeedBean.count()/ps);
}
}
Ta-Daaaa with less than 200 LOC we have a completely working backend.
The WebApp
The frontend is an Angular app made responsive using bootstrap. I won’t show the whole code since it is very minimal (you can see it on GitHub). The app is made of two components: one that shows the articles and one that requests pages.
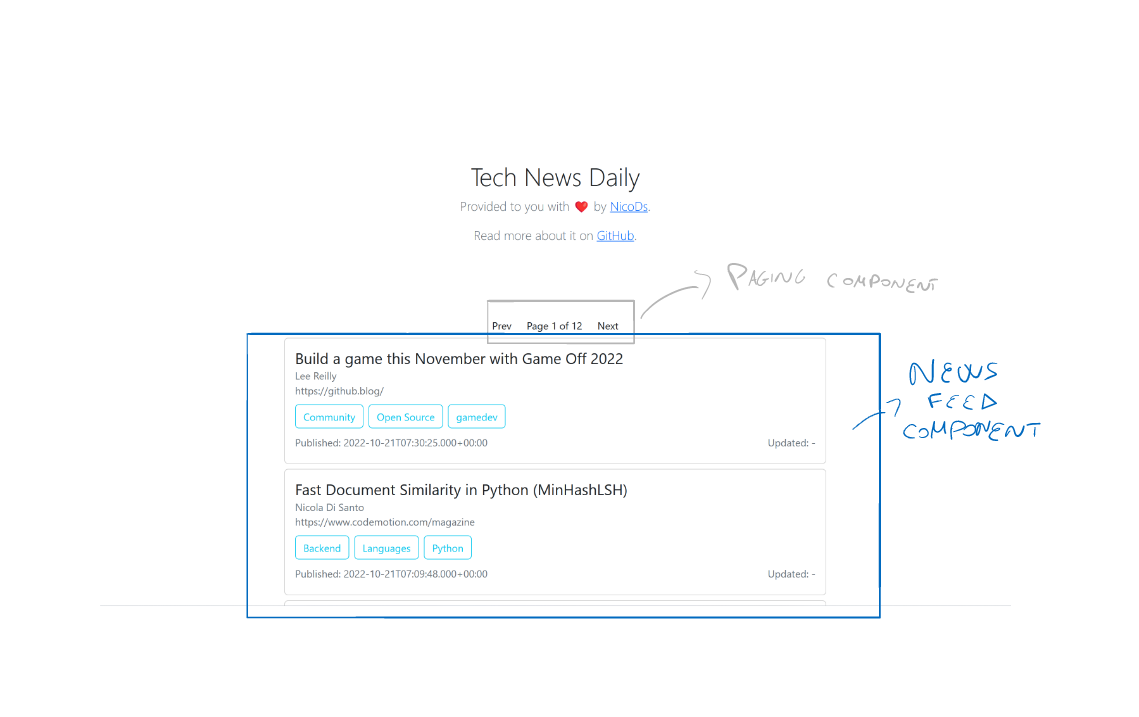 The core of the app is the IndexService, which keeps track of the page the user is visiting.
The core of the app is the IndexService, which keeps track of the page the user is visiting.
import { Injectable } from '@angular/core';
import { BehaviorSubject } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class IndexService {
idx: BehaviorSubject<number>;
constructor() {
this.idx = new BehaviorSubject(0);
}
next(){
this.idx.next(this.idx.getValue() + 1)
}
prev(){
this.idx.next(this.idx.getValue() - 1)
}
goto(n: number){
this.idx.next(n)
}
}
The current page number (idx in the code) is observed from the components to update the data each time the value changes:
export class ListComponent implements OnInit {
feedList: Feed[];
index: number;
constructor(private http: HttpClient, private idxService: IndexService) {
this.feedList = [];
this.index = 0;
}
ngOnInit(): void {
this.idxService.idx.subscribe(value => {
this.index = value;
this.http.get<Feed []>(`${environment.endpoint}/feeds/${this.index}`)
.subscribe(feeds => this.feedList = feeds);
})
}
...
}
Deploy
WebApp
To deploy the solution I have decided to use GitHubPages for the Web App. The steps to build are simple:
ng build --configuration=production
then push the file into the project home. One note about Angular build: it generates an index.html where the js scripts are imported with module type
<script src="main.3cc1e1de394d1b26.js" type="module"></script>
to be properly served from GitHub Pages they must be of type application/javascript:
<script src="main.3cc1e1de394d1b26.js" type="application/javascript"></script>
The Poller
The poller is a very lightweight process that runs every minute, so I let it run on my PC that is on 12 hours a day. I have first created an uber jar, using the Quarkus utilities:
mvnw package -Dquarkus.package.type=uber-jar
Then I have containerized the app with
FROM registry.access.redhat.com/ubi8/openjdk-17:1.11
ENV LANGUAGE='en_US:en'
COPY --chown=185 target/*-runner.jar /deployments/
EXPOSE 8080
USER 185
ENV JAVA_OPTS="-Dquarkus.http.host=0.0.0.0 -Djava.util.logging.manager=org.jboss.logmanager.LogManager"
ENV JAVA_APP_JAR="/deployments/*-runner.jar"
docker build -f .\src\main\docker\Dockerfile.uberjar .
Instead of pushing it to some registry, I have exported it using
docker save --output poller.container <container_id>
Loaded into the final machine with
docker load --input poller.container
And, set it to run automatically at startup
docker run --restart always <image>
The API
The API is running on Google Cloud Runner, which is the serverless solution for the endpoint suggested by Google, it is like a lambda and it has 2 milly free calls every month. Not bad for a broke developer ![]() .
Building the API code is where the magic happens: Quarkus, with the support of GraalVM let you transform Java Code into a native executable. If you have Docker installed you do not have to configure anything, you can run
.
Building the API code is where the magic happens: Quarkus, with the support of GraalVM let you transform Java Code into a native executable. If you have Docker installed you do not have to configure anything, you can run
mvnw package -Pnative -Dquarkus.native.container-build=true
And you have a perfectly running x64 Linux native image. To deploy it to Google Cloud Run you need an account, a project, and the Google Cloud CLI installed. Then you can simply containerize the image and push it into the Google Registry:
FROM quay.io/quarkus/quarkus-micro-image:1.0
WORKDIR /work/
RUN chown 1001 /work \
&& chmod "g+rwX" /work \
&& chown 1001:root /work
COPY --chown=1001:root target/*-runner /work/application
EXPOSE 8080
USER 1001
CMD ["./application", "-Dquarkus.http.host=0.0.0.0"]
docker tag <image> gcr.io/<project id>/endpoint
And now you can use the Cloud Run panel to select the container as the image to run.
 The key role of the native image here is the fast startup of the API service, which plays a key role in the responsiveness of the serverless solution:
The key role of the native image here is the fast startup of the API service, which plays a key role in the responsiveness of the serverless solution:
2022-10-21 11:06:40,514 INFO [io.quarkus] (main) news-aggregator 0.0.1 native (powered by Quarkus 2.13.2.Final) started in 0.286s. Listening on: http://0.0.0.0:8080
How to deploy your own
If you want to use the code to build your news aggregation website, here is the step you need to follow.
- Fork the repo and enable GitHub Pages.
- Create an Atlas MongoDB cluster following the procedure on the website
- create a database named Feeds
- creare a collection named NewsFeed
- Once you have an instance up and running, copy the connection string and paste it into
feed-poller/src/main/resources/application.propertiesandnews-aggregator/src/main/resources/application.properties - Set your own feeds into
feed-poller/src/main/resources/application.properties - Run everything locally to see if it works
- start the poller in dev mode (
cd feed-poller && quarkus dev) - start the API in dev mode (
cd news-aggregator && quarkus dev) - serve the webapp (
cd news-html && ng serve)
- start the poller in dev mode (
- Follow the deployment steps detailed previously to make the website available to the public.
Now what?
The project was really useful to deepen some interesting frameworks I was curious about. I think it has also the potential to become something more complex and interesting, for example adding support for users, allowing different users to have custom feeds, exposing common feeds to a subset of users, adding push notifications, distribution lists etc. To extend it, an effort is required but resources are constrained so, for now, it will remain a funny weekend project, hosted until it will be free.

Nicola Di Santo
A Person who loves tech, bikes and fighting sports