
CDC is hot and you don't know about it!
- 17 mins
The most interesting breakthrough in the software industry from a technical point of view generally goes unnoticed by most of the people working in tech. I like to think about it as the Nobel prize: nobody understands and nobody cares about you and your useless research until you make a lot of money with it or you win the Nobel prize. Sometimes the industry lets you believe, with an incredibly expensive marketing campaign, that there is a revolution in progress thanks to the technology they want to sell. Then the hype goes away and tech people start realizing that the cloud is just server rental with very high cost and low benefits, that blockchain is useless unless you want to revolutionize the economic system, and so on… Now it’s the moment of A.I., a bunch of matrix multiplications, which really few people in the world really understand, and that consumes tons of energy. But the real innovative - maybe boring - breakthroughs are not known enough. An example is Debezium, an open-source Change Data Capture (CDC) platform that might revolutionize the way you think about your services and data platform.
In Brief
On the web page, it is described as
an open-source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
It allows you to listen to the database’s internal log and stream row-level changes wherever you want. If you have a full-text search service you might use it to easily upload the search index with a dedicated consumer of the records. If you are building a data platform you might use it to replicate in near real-time all the changes in your relational database and historicize the data or replicate the table for analytical workloads.
In the following example, we are going to use only its engine to track the changes of a single table and log them all into a dedicated table on the same database. It might sound stupid but it is an actual use case I have implemented for a client, that needed to track all the changes made on a few tables. He has tried with database triggers but the performance degradation was significant (bulk insert of 24K row went from 1 to 30 minutes).
The Experiment
You can find the whole project on GitHub at:
And some useful documentation to customize the project at:
Demo
First of all, we are going to create a database and we will use Docker for that
version: '3.8'
services:
postgres:
container_name: pg-local
image: postgres
hostname: localhost
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
restart: unless-stopped
volumes:
- ./db_init_scripts:/docker-entrypoint-initdb.d
command:
- "postgres"
- "-c"
- "wal_level=logical"
Then we define db init scripts into the db_init_scripts folder:
#!/bin/bash
set -e
set -x
psql -v ON_ERROR_STOP=1 --username "$POSTGRES_USER" --dbname "$POSTGRES_DB" <<-EOSQL
create schema tracking;
CREATE TABLE public.debezium_offset_storage (
id varchar(36) NOT NULL PRIMARY KEY,
offset_key varchar(1255) NULL,
offset_val varchar(1255) NULL,
record_insert_ts timestamp NOT NULL,
record_insert_seq int4 NOT NULL
);
CREATE TABLE public.dummy_table (
username text NOT NULL PRIMARY KEY,
address text
);
EOSQL
Now we can start the database and capture changes to the table dummy_table running the jar
# start the database
docker compose -up -d
# download the jar
wget -O debezium-demo.jar https://github.com/nicoDs96/debezium-engine-demo/releases/download/v0.0.1-alpha/debezium-demo.jar
# start CDC
java --jar debezium-demo.jar
Now all the operations made on the table dummy_table will be recorded under tracking.dummy_table_tracking:
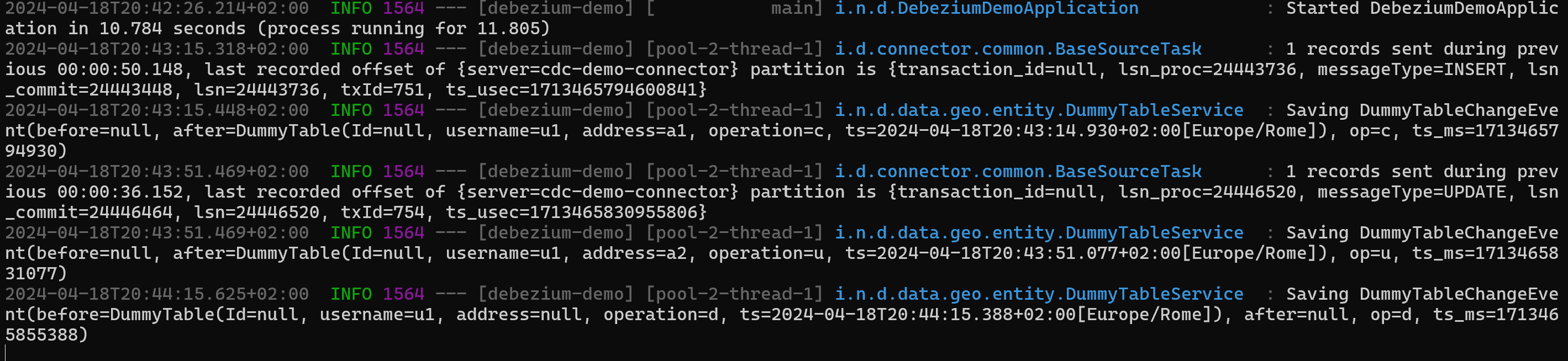
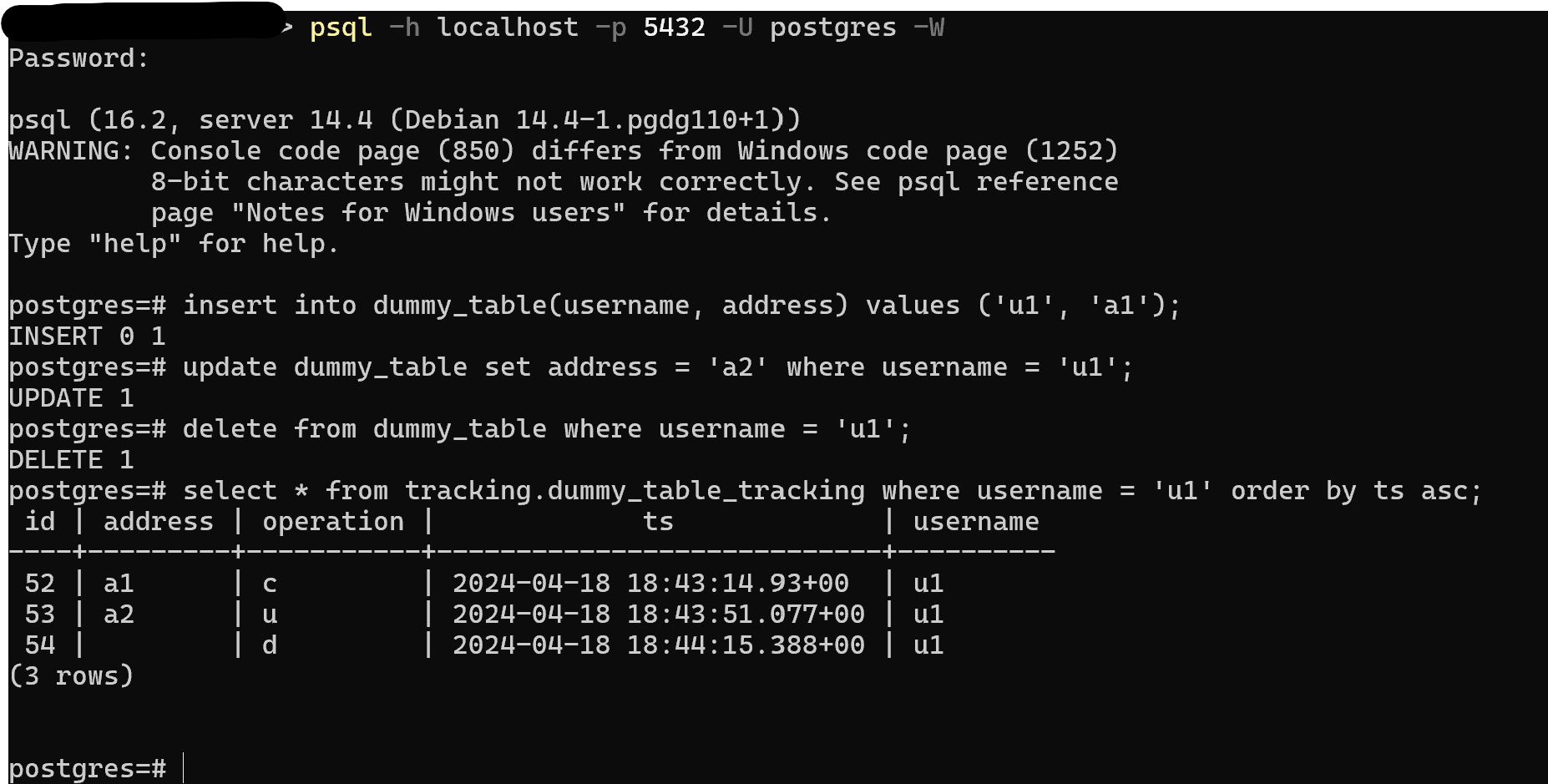
Looks like magic but it’s not. Let’s break it down.
Spring Boot
We need to create a Spring Boot project with the following dependencies
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-api</artifactId>
<version>${debezium.version}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-embedded</artifactId>
<version>${debezium.version}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-storage-jdbc</artifactId>
<version>${debezium.version}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-postgres</artifactId>
<version>${debezium.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-cloudwatch2</artifactId>
</dependency>
</dependencies>
The project will have the following structure
./
├── PostgresLocal # database docker files and scripts
│ └── db_init_scripts
├── src
│ ├── main
│ │ ├── java
│ │ │ └── it
│ │ │ └── nicods
│ │ │ └── debeziumdemo # Spring boot entrypoint
│ │ │ ├── config # debezium configuration
│ │ │ ├── data # data utilities
│ │ │ │ └── entity # entity definition
│ │ │ └── listener # main logic
│ │ └── resources
│ │ └── ddl
│ └── test
│
└── target
Under data/entity we are going to define the entity corresponding to the table where we will log all the changes to the main table, the JPA repository, and some utility classes to serialize/deserialize data from deuterium to the database.
Looking at the entity definition below we can notice three extra fields in the class:
- The id of the modified record used as primary key (note that this id is like a surrogate key into a data warehouse because the natural pk isn’t sufficient)
- The operation field, telling if the record has been created (c), updated (u), deleted (d). The read (r) is reserved for snapshot, check the doc for details.
- The timestamp of the captured change.
@Entity @Table(name = "dummy_table_tracking", schema = "tracking") @Getter @Setter @ToString @NoArgsConstructor @AllArgsConstructor @Builder public class DummyTable { @Id @GeneratedValue private Integer Id; private String username; private String address; private String operation; private ZonedDateTime ts; }The JPA repository:
@Repository public interface DummyTableRepository extends JpaRepository<DummyTable, Integer> {}The class for the Debezium JSON representation of CDC data:
@AllArgsConstructor @NoArgsConstructor @Getter @Setter @ToString public class DummyTableChangeEvent { private DummyTable before; private DummyTable after; private String op; private Long ts_ms; }
Now we can wrap everything defined above together and define a service capable of dealing with captured change events for the table of interest. The service will consume the event and simply record it into the designated table.
@Slf4j
public class DummyTableService extends TrackingService<DummyTableChangeEvent> {
public DummyTableRepository repository;
public DummyTableService(DummyTableRepository repository){
this.repository =repository;
}
@Override
@Transactional
public void handleEvent(DummyTableChangeEvent record) {
if(record!=null){
DummyTable bl=null;
DummyTable after = record.getAfter();
DummyTable before = record.getBefore();
if(after!=null) { //in case of delete after is null and before is valued
bl = after;
}
else if (before!=null){ //in case of delete after is null and before is valued
bl = before;
}
if(bl!= null){
ZonedDateTime zdt = ZonedDateTime.ofInstant(Instant.ofEpochMilli(record.getTs_ms()), ZoneId.systemDefault());
bl.setTs(zdt);
bl.setOperation(record.getOp());
log.info("Saving {}", record);
repository.save(bl);
}else {
log.error("Before and After are both null {}", record);
}
}else{
log.debug("Change record is null");
}
}
}
The TrackingService extended by the service class is a simple utility to deserialize Json using Jackson’s ObjectMapper:
public T deserialize(String sourceRecordValue, Class<T> clazz) throws IOException {
if (Objects.nonNull(sourceRecordValue)) {
ObjectMapper mapper = new ObjectMapper();
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
return mapper.readValue(sourceRecordValue, clazz);
}
return null;
}
Now we need to create the actual Debezium Engine that is capable of reading the database WAL and streaming all the events of interest to our DummyTableService. The class is responsible for
- create the engine
- start the engine
- pass the event to the appropriate service to handle it
- terminate the engine
@Slf4j
@Service
public class DebeziumSourceEventListener {
//This will be used to run the engine asynchronously
private final Executor executor;
//DebeziumEngine serves as an easy-to-use wrapper around any Debezium connector
private final DebeziumEngine<ChangeEvent<String, String>> debeziumEngine;
@Autowired
private DummyTableRepository dummyTableRepository;
public DebeziumSourceEventListener(
Configuration postgresConnector) {
// Create a new single-threaded executor.
this.executor = Executors.newSingleThreadExecutor();
// Create a new DebeziumEngine instance.
//TODO: understand Configuration origin
this.debeziumEngine =
DebeziumEngine.create(Json.class)
.using(postgresConnector.asProperties())
.notifying(this::handleChangeEvent)
.build();
}
private boolean handleChangeEvent(ChangeEvent<String, String> record) {
log.debug("JSON Record {}", record);
log.debug("JSON Key {}", record.key());
log.debug("JSON Value {}", record.value());
log.debug("JSON Headers {}", record.headers());
log.debug("JSON Destination {}", record.destination());
String sourceRecordValue = record.value();
DummyTableService dummyTableService = new DummyTableService(dummyTableRepository);
try{
switch (record.destination()){
case "cdc-demo-connector.public.dummy_table":
DummyTableChangeEvent dummyTableChangeEvent = dummyTableService.deserialize(sourceRecordValue, DummyTableChangeEvent.class);
log.debug("JSON DESER {}", dummyTableChangeEvent);
dummyTableService.handleEvent(dummyTableChangeEvent);
return true;
default:
log.error("Ignoring unknown destination {}", record.destination());
break;
}
}catch (IOException e){
log.error("Error deserializing source record value", e);
return false;
}
return false;
}
@PostConstruct
private void start() {
this.executor.execute(debeziumEngine);
}
@PreDestroy
private void stop() throws IOException {
if (this.debeziumEngine != null) {
this.debeziumEngine.close();
}
}
}
Note that to create the engine we need give to it the configurations loaded from the application.properties, defined in config/DebeziumConnectorConfig. The most importants are:
- offset.storage telling to store the progress made reading WAL to the DB so that in case of failure or restart it can continue from where it left
- table.include.list telling the tables where changes must be captured
- snapshot.mode telling if to perform and how to perform a snaposhot of the tables before starting
@Configuration
public class DebeziumConnectorConfig {
@Value("${spring.datasource.url}")
private String postgresUrl;
@Value("${debezium.database.hostname}")
private String postgresHostname;
@Value("${debezium.database.dbname}")
private String postgresDBName;
@Value("${debezium.database.port}")
private String postgresPort;
@Value("${spring.datasource.username}")
private String postgresUsername;
@Value("${spring.datasource.password}")
private String postgresPassword;
@Value("${debezium.schema.include.list}")
private String databaseSchemaIncludeList;
@Value("${debezium.table.include.list}")
private String databaseTableIncludeList;
@Value("${debezium.connector.name}")
private String connectorName;
@Value("${debezium.plugin.name}")
private String pluginName;
@Value("${debezium.snapshot.mode}")
private String snapshotMode;
@Bean
public io.debezium.config.Configuration mongodbConnector() {
Map<String, String> configMap = new HashMap<>();
//This sets the name of the Debezium connector instance. It’s used for logging and metrics.
configMap.put("name", connectorName);
//This specifies the Java class for the connector. Debezium uses this to create the connector instance.
configMap.put("connector.class", "io.debezium.connector.postgresql.PostgresConnector");
configMap.put("database.user", postgresUsername);
configMap.put("database.dbname", postgresDBName);
configMap.put("database.hostname", postgresHostname);
configMap.put("database.password", postgresPassword);
configMap.put("database.port", postgresPort);
//This sets the plugin to use
configMap.put("plugin.name", pluginName);
//This sets the Java class that Debezium uses to store the progress of the connector.
// In this case, it’s using a JDBC-based store, which means it will store the offset in a relational database.
configMap.put("offset.storage", "io.debezium.storage.jdbc.offset.JdbcOffsetBackingStore");
//This is the JDBC URL for the database where Debezium stores the connector offsets (progress).
configMap.put("offset.storage.jdbc.url", postgresUrl);
configMap.put("offset.storage.jdbc.user", postgresUsername);
configMap.put("offset.storage.jdbc.password", postgresPassword);
// This writes offsets to plain file
//configMap.put("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");
//configMap.put("offset.storage.file.filename", "./debezium-offset.dat");
configMap.put("offset.flush.interval.ms", "2000");
//This prefix is added to all Kafka topics that this connector writes to.
configMap.put("topic.prefix", "cdc-demo-connector");
//This is a comma-separated list of Postgres database names that the connector will monitor for changes.
//configMap.put("schema.include.list", databaseSchemaIncludeList);
configMap.put("table.include.list", databaseTableIncludeList);
//this set the snapshot mode
configMap.put("snapshot.mode", snapshotMode);
// this includes/exclude the schema in the message
configMap.put("converter.schemas.enable", "false");
//When errors.log.include.messages set to true, then any error messages resulting from failed operations
// are also written to the log.
configMap.put("errors.log.include.messages", "true");
return io.debezium.config.Configuration.from(configMap);
}
}
Conclusions
In this demo, we have explored a custom configuration for a very particular use case, but with the standard architecture using Kafka and enabling snapshots, we might be able, for example, to replicate an entire database on another system with ease, and without defining complex pipelines. We might be able to make our services reactive to other services-managed entities and so on. The more I think about it and more use cases come to my mind for this astonishing piece of innovation.

Nicola Di Santo
A Person who loves tech, bikes and fighting sports