Designing A Deep Reinforcement Learning Trading Bot With PyTorch
- 6 minsA few years ago, at university, to pass the exam of Neural Networks class we should implement a recent paper and try to replicate results. At that time a friend of mine wrote a paper based on his thesis for his bachelor’s degree about a deep reinforcement trading bot that was able to trade bitcoin and he claims the bot could make profits. I was a bit skeptical about it and decided to implement a personal version of the bot, test it, and use it as the final project of the NN class. Here I am going to describe it.
Where To Find It
You can find the project on GitHub: Project Repo.
The repo also contains a report I used to describe the bot to the professor at the time, with some pills of background math theory.
Feel free to open an issue or a pull request if you want to contribute.
Background
In the paper we based the implementation on the authors try to adapt some Deep Reinforcement
Learning techniques, namely DQN, Double DQN, and Dueling Double
DQN, to allow an agent to trade cryptocurrency stocks. The trading
environment simulation gives the possibility to either buy, hold or sell a position. The profit made during trading is measured with the Sharpe ratio index or a simple profit difference function.
In the reinforcement learning field, the agent is someone with a goal that should interact with an environment to reach its goal. You can think about it as your robot vacuum cleaner whose goal is to clean your house. An agent \(A\) can have states \(s_1, .., s_n\), like resting, cleaning, moving, etc., and can perform some actions \(a_1, .., a_m\) on the environment, like “suck the dust” or “move to another room”. Whenever an agent acts on the environment he modifies it, so the environment moves to a new state \(s_{t+1}\) and the agent collects a reward \(r_t\) telling him if he did a step towards its goal or not.
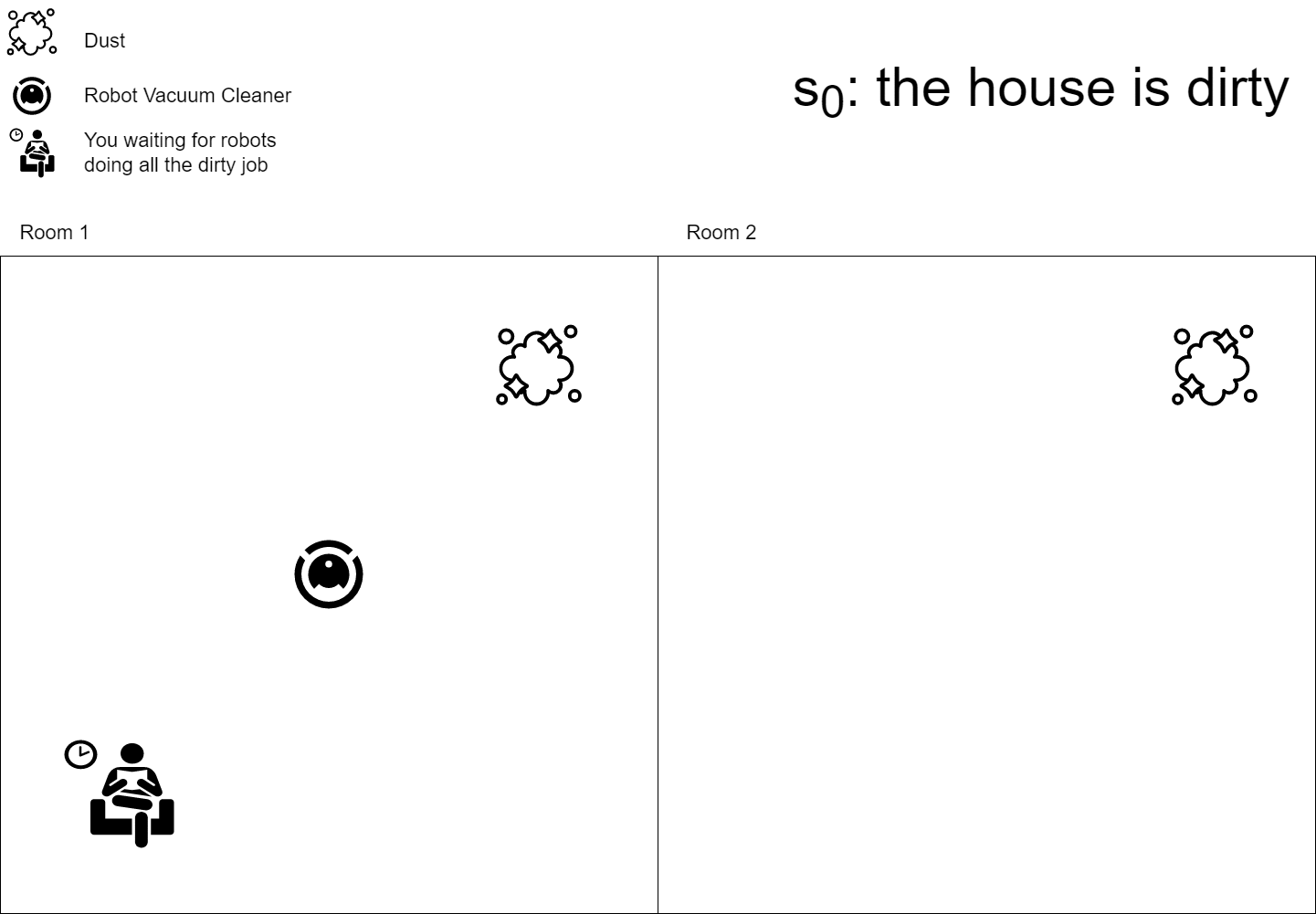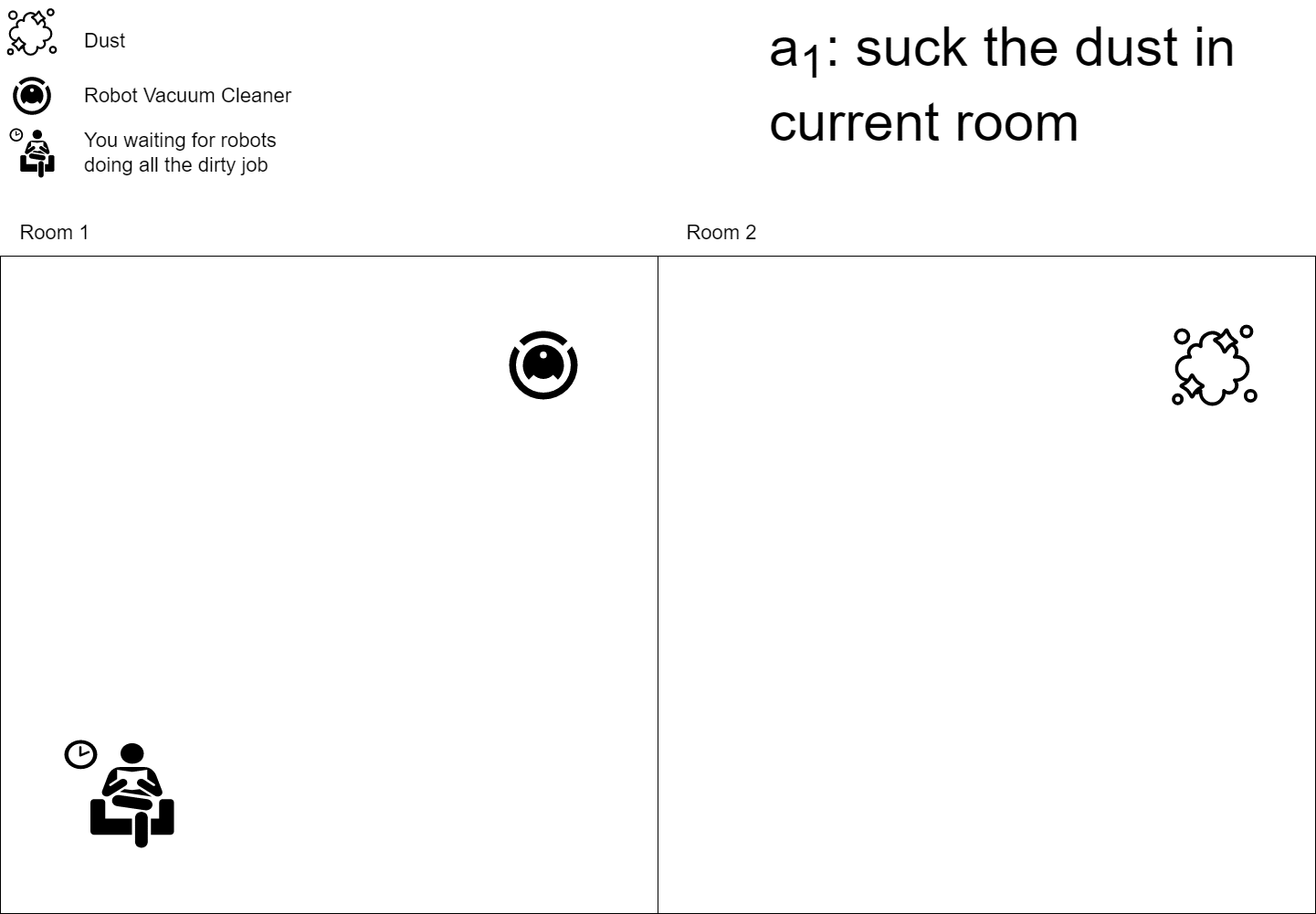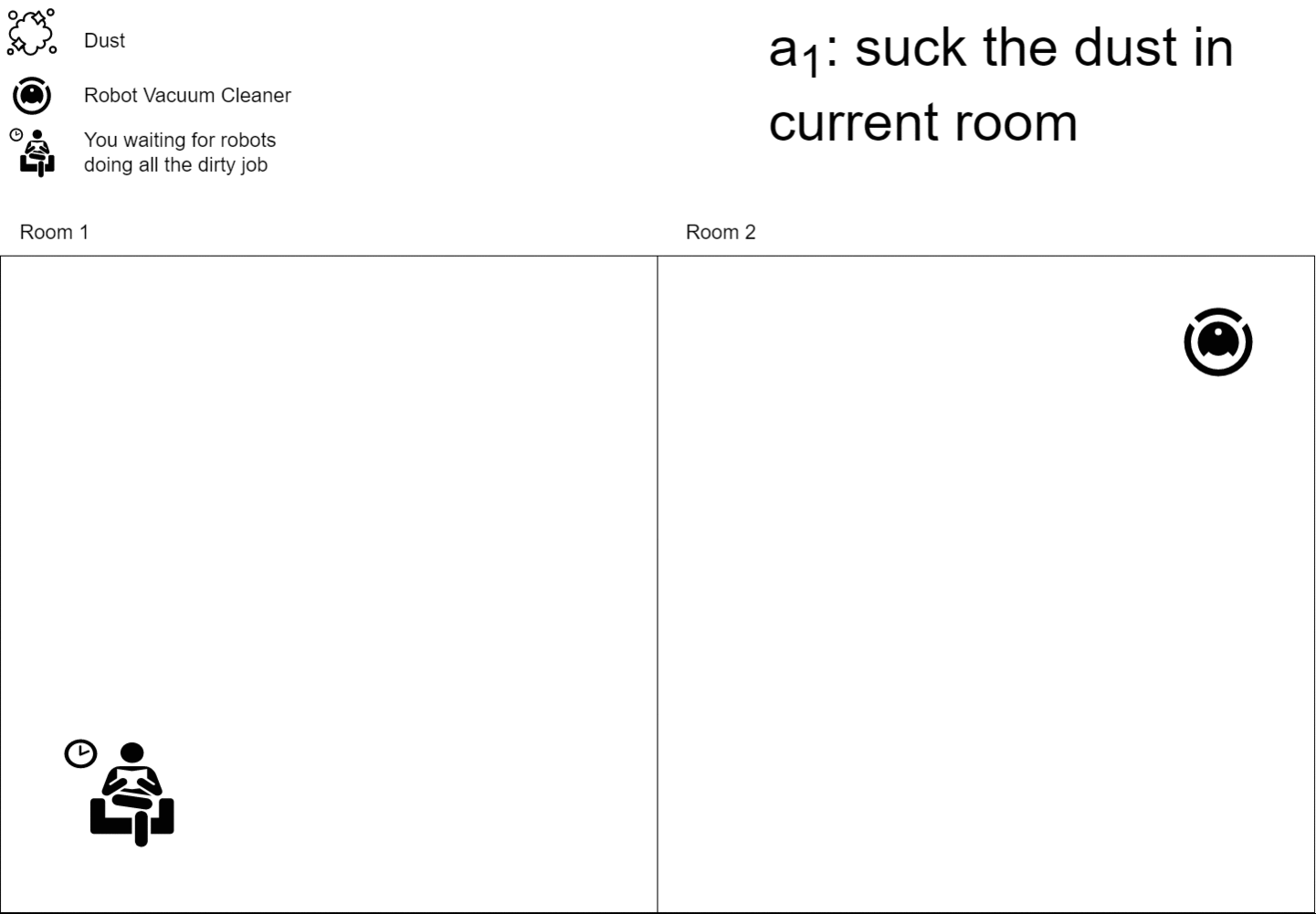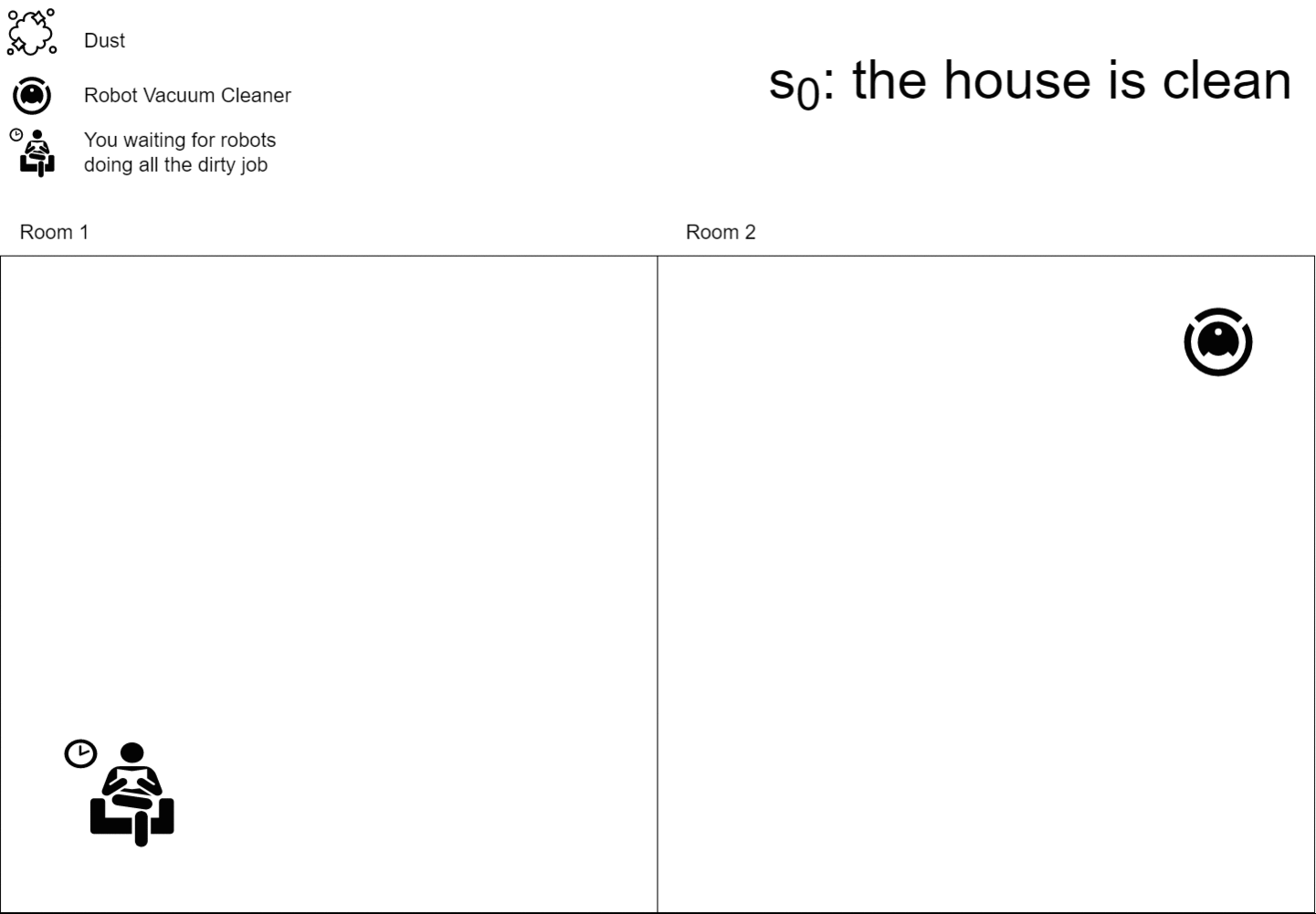 The whole deep reinforcement learning world is based on a simple fact: neural networks are universal function approximators, we can simply create a NN model and train it to resemble the Q functions or whatever RL functions you plan to use.
The whole deep reinforcement learning world is based on a simple fact: neural networks are universal function approximators, we can simply create a NN model and train it to resemble the Q functions or whatever RL functions you plan to use.
The Environment
We can think of the Environment as a wrapper around our data with minimal access methods and a bit of logic. In detail, you can only access data by calling the method def get_state(self):. it gives to you the current stock price window, corresponding to the environment state.
Then you can interact with it only with the def step(self, act): method. It simply acts as the Agent on the environment (the input parameter), computes the reward for the agent and it updates some data structures to keep track of some econometric indexes during time, used to evaluate the model.
In detail, an Agent can either buy, sell, hold/do-nothing. If the agent has bought at a given price and then in the next step it does nothing this means he is holding a position because he thinks the price is going to rise. If the Agent has no position and he does not buy then he is doing nothing because he thinks it is not convenient to buy now.
The Agent
The Agent is a wrapper for the model and it takes care of the training and inference logic. The test phase def test(self, env_test, model_name=None, path=None) in the agent assumes you have an already trained model and you have exported it. It then loads the exported model into one of the models defined into models.py according to the parameters and then starts the canonical observe-act-collect loop, saving all the metrics needed to evaluate the model.
The training phase def train(self, env, path, num_episodes=40): is a bit more complex apparently because it included model optimization. The loop becomes observe-act-collect-optimize and the optimize phase requires a bit of background knowledge to be mastered (perfectly covered on the pytorch doc, the code here is only an adaptation to a different kind of use case).
The code in the repo comes with some pretrained models profit_reward_double_ddqn_model, profit_reward_double_dqn_model, profit_reward_dqn_model, sr_reward_double_ddqn_model, sr_reward_double_dqn_model, sr_reward_dqn_model and the main.py only evalutes those pre-trained moedels. If you want also to train them you should check the train_test.py script.
Replay Memory Buffer
The replay memory buffer is a useful tool that is perfectly explained in this article from Jordi Torres that I would like to quote:
We are trying to approximate a complex, nonlinear function, Q(s, a), with a Neural Network. To do this, we must calculate targets using the Bellman equation and then consider that we have a supervised learning problem at hand. However, one of the fundamental requirements for SGD optimization is that the training data is independent and identically distributed and when the Agent interacts with the Environment, the sequence of experience tuples can be highly correlated. The naive Q-learning algorithm that learns from each of these experiences tuples in sequential order runs the risk of getting swayed by the effects of this correlation. We can prevent action values from oscillating or diverging catastrophically using a large buffer of our past experience and sample training data from it, instead of using our latest experience. This technique is called replay buffer or experience buffer. The replay buffer contains a collection of experience tuples (S, A, R, S′). The tuples are gradually added to the buffer as we are interacting with the Environment. The simplest implementation is a buffer of fixed size, with new data added to the end of the buffer so that it pushes the oldest experience out of it. The act of sampling a small batch of tuples from the replay buffer in order to learn is known as experience replay.
Conclusion
Although the DRL is always used to play video games with AI, it is interesting to apply them also to other fields, since they are very promising AI methods. Although very exciting, I invite you to be always a bit skeptical about what you read. If you pay attention to both the report of this project and the original paper it is based on, you will note that there isn’t any error plot or similar metrics. This is likely a sign that the results you are reading are not telling the whole truth. Indeed, in my report, I deliberately hid them to get a higher grade on the exam (and luckily it worked out), but the truth is that the models do not have a significant decrease in error. In brief, they do not learn anything and act almost randomly at each step.

Nicola Di Santo
A Person who loves tech, bikes and fighting sports